AWS Vaultを利用してAssume Roleする
はじめに
IAM Userを利用してAWSマネジメントコンソールにアクセスしたり、AWS CLIを実行している人がいらっしゃるかもしれません。 ただし、IAM Userに強い権限をもったIAM Policyをアタッチするのは少し怖いです。 AWS CLIを利用している場合にはアクセスキーとシークレットキーを払い出していますし、これらが第三者へ漏洩してしまう可能性もあります。 そこで、IAM UserにアタッチするIAM Policyの権限はできる限り最小限に抑えたいです。 そして、Assume Roleによって必要な権限をもつIAM Roleへスイッチする方が良いかと思います。 今回のブログでは、IAM Userの作成とAWS Vaultを利用したAssume Roleの実施についてまとめます。 なお、AWS Vaultのインストールについてはこちらを参考にしてください。
IAM Userの作成
基本的に、IAM UserにはMFAを有効化するための権限のみを許可したPolicyを設定します。
{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": [ "iam:EnableMFADevice", "iam:ListUsers", "iam:CreateVirtualMFADevice", "iam:ListMFADevices", "iam:GetUser" ], "Resource": "*" } ] }
IAM User Groupの作成
上記で作成したIAM Userに対してAssume Roleを許可するPolicyは、該当PolicyがアタッチされたIAMのUser Groupを作成し、そこへIAM Userを所属させることにします。 User Groupに設定するPolicyは以下の通りです。
{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": "sts:AssumeRole", "Resource": "arn:aws:iam::<account_id>:role/<role_name>", "Condition": { "BoolIfExists": { "aws:MultiFactorAuthPresent": "true" } } } ] }
ResourceではAssume Roleの対象となるIAM RoleのARNを指定しています。 適切なPolicyを付与したIAM Roleを作成してください。 また、Condition句では、MFAが有効になっていることを確認するものです。
IAM UserのAWS CredentialsをAWS Vaultに格納する
以下のコマンドを実行することにより、AWS VaultにAWS Credentialsが格納されます。
$ aws-vault add <設定したいプロファイル名> Enter Access Key Id: ABDCDEFDASDASF Enter Secret Key: %%%
<設定したいプロファイル名>には、該当IAM Userを識別するためのプロファイル名を任意で設定することができます。 例えば、devとした場合には、このコマンドの実行完了後に以下の記述がConfigファイルに追記されます。
[profile dev]
AWS ConfigファイルにAssume Role用のプロファイルを記述する
Assume Roleの情報をAWS Configファイルに記述します。 source_profileは先に作成したIAM Userのプロファイルを指定し、対象となるIAM RoleのARNやMFAシリアルを設定します。
[profile admin] source_profile=<AWS Vaultで作成したプロファイル名> role_arn=arn:aws:iam::<account_id>:role/<role_name> mfa_serial=arn:aws:iam::<account_id>:mfa/<iam_user_name>
動作確認
最後に、設定に対して正常に動作するか確認します。
aws-vault exec admin -- aws sts get-caller-identity
Enter MFA code for arn:aws:iam::<account_id>:mfa/<iam_user_name>: ******
{
"UserId": "<user_id>",
"Account": "<account_id>",
"Arn": "arn:aws:sts::<account_id>:assumed-role/<role_name>/<session_token>"
}
さいごに
いかがでしたでしょうか。これを読んでいただいた人のお役に立てれば幸いです。
Step FunctionsによるCodeBuildの呼び出しと成功・失敗処理をハンドリングする
はじめに
Step FunctionsからCodeBuildを呼び出すことができ、CodeBuildで実施した処理の成功・失敗に応じたハンドリングを行うことができます。 そして、Step Functionsを利用することでCodeBuild実行に使用した環境変数やその他情報を後続の処理に渡すことも可能となります。 今回の投稿では、上記を実現するためのアーキテクチャなどを紹介できればと思います。よろしければ、最後までご覧いただければ幸いです。
構成図
以下は今回の簡単なアーキテクチャとなります。

Terraformコード
アーキテクチャでは、AWSリソースとしてStep Functions、CodeBuild、各種Lambda関数がありますが、今回はStep Functionsに焦点を絞ってお伝えします。
以下は、Step Functionsの構築におけるTerraformコードを記載します。 大部分はState Machineの記述になります。ブロックごとに説明していきます。
resource "aws_sfn_state_machine" "example" { name = "example-state-machine" role_arn = "<iam_role_arn>" definition = jsonencode({ StartAt = "StartCodeBuild" States = { StartCodeBuild = { Type = "Task" Resource = "arn:aws:states:::codebuild:startBuild.sync" Parameters = { ProjectName = "<codebuild_project_name>", EnvironmentVariablesOverride = [ { Name = "HOGE", "Value.$" = "$.Hoge", Type = "PLAINTEXT", }, { Name = "FUGA", "Value.$" = "$.Fuga", Type = "PLAINTEXT", } ] }, ResultSelector = { "EnvironmentVariables.$" = "$.Build.Environment.EnvironmentVariables" } Next = "SuccessNotification", Catch = [ { ErrorEquals = ["States.TaskFailed"], Next = "FailedNotification", } ] }, FailedNotification = { Type = "Task" Resource = "<failed_notification_function_arn>" End = true }, SuccessNotification = { Type = "Task", Resource = "<success_notification_function_arn>" End = true }, } }) }
まずは、CodeBuildを呼び出すState部分のTerraformコードについて解説します。 該当部分はStartCodeBuildのブロックとなります。まずは、Resourceですがこちらはarn:aws:states:::codebuild:startBuild.syncという値になっています。 これはCodeBuildを呼び出す設定値なのですが、同期呼び出しであることを意味します。この設定により、CodeBuildの処理が完了するまで待機します。
Parametersでは、CodeBuildのAPIのリクエストパラメータを設定していきます。上記のTerraformコード例では、実際に呼び出すCodeBuildのProject名、Project上で利用する環境変数を指定しています。 その他のパラメータについてはこちらをご覧ください。 特に、環境変数を設定しているEnvironmentVariablesOverrideを見ていきます。Nameは環境変数名、Typeは環境変数のデータ形式をそれぞれ表しています。 ここで注目すべき点は、"Value.$" = "$.Hoge"や"Value.$" = "$.Fuga"といった箇所です。本来は、"Value" = "指定したい任意の値"と記述するところなのですが、今回のケースでは、環境変数として設定する値をStep Functions起動時の入力パラメータから指定するためにこのような記載になっています。また、ResultSelectorでは、CodeBuildが行った処理結果の一部を抽出しています。
最後に、CodeBuildの処理の成功・失敗に沿ったステートの指定を見ていきます。処理が成功した場合に対しては、単純にNextを利用して、成功時の処理を実施するステートを指定するだけです。 一方、失敗した場合に対してはCatchを利用します。上記のTerraformコードでは、失敗時のErrorの種類とその際に処理を実施するステートを指定します。Errorの際にはその原因や入力された値などが次のステートへ渡されます。
さいごに
いかがでしたでしょうか。今回はStep FunctionsでCodeBuildを呼び出し際の処理の成功・失敗に対するハンドリングを適用するためのState Machineについて記載しました。 どこかの誰かの役に立てば幸いです。
TerraformによるKinesis Data Firehoseの動的パーティショニングの設定
はじめに
Kinesis Data Firehoseは、Amazon Simple Storage Service(Amazon S3)、Amazon Redshiftなどやサードパーティサービスプロバイダが所有するHTTPエンドポイントなどの送信先へストリーミングデータのリアルタイム配信を実現するマネージドサービスです。Kinesis Data Firehoseのストリーミングデータ受信元としてAWSサービスでは、Kinesis Data StreamsやKinesis Data Analyticsなどがあります。 今回は、このKinesis Data Firehoseの動的パーティショニングをTerraformで設定する方法を記載します。 動的パーティショニングを使用すると、データ内のキーを利用してKinesis Data FIrehoseでストリーミングデータを継続的にパーティショニングし、これらのキーでグループ化されたデータを、対応するS3プレフィックスに配信できます。
Terraformコード
以下はKinesis Data Firehoseの動的パーティショニングを設定するTerraformのサンプルコードです。 ここで注意するのは、動的パーティショニングはKinesis Data Firehoseの初回作成時のみ設定可能ということです。 また、バッファサイズの設定は少なくとも64MBでないとならない点もあります。
resource "aws_kinesis_firehose_delivery_stream" "example" { name = "<kinesis_firehose_delivery_stream_name>" destination = "extended_s3" extended_s3_configuration { bucket_arn = "<destination_S3_bucket_arn>" role_arn = "<iam_role_arn>" buffer_size = 64 buffer_interval = 60 prefix = "!{partitionKeyFromQuery:Id}/!{timestamp:yyyy}/!{timestamp:MM}/!{timestamp:dd}/!{timestamp:HH}/" error_output_prefix = "errors/!{timestamp:yyyy}/!{timestamp:MM}/!{timestamp:dd}/!{timestamp:HH}/!{firehose:error-output-type}/" dynamic_partitioning_configuration { enabled = true } processing_configuration { enabled = true processors { type = "AppendDelimiterToRecord" parameters { parameter_name = "Delimiter" parameter_value = "\\n" } } processors { type = "MetadataExtraction" parameters { parameter_name = "JsonParsingEngine" parameter_value = "JQ-1.6" } parameters { parameter_name = "MetadataExtractionQuery" parameter_value = "{Id:.Id}" } } } } }
動的パーティショニングの設定
動的パーティショニングの設定自体は以下の部分になります。
dynamic_partitioning_configuration { enabled = true }
ただし、今回はS3バケットへのデータ配信のPrefixとして受信したJSONデータ内のIdを利用する場合には、processing_configurationがの設定も必要となります。
さいごに
今回は備忘のためにサンプルコードのみを記載しました。 お役立ちできれば幸いです。
IntelliJ IDEAにおけるLive Templatesでの快適なTerraformライフ
はじめに
僕はIaC(Infrastructure as Code)については多くの場合に関してTerraformを利用します。 そのような中で同じようなコードを書くことが多々あります。AWS Lambda Functionを作成する際のAWS IAM Roleなどはその最たる例かもしれません。 今までは恥ずかしい話ですが、粛々と同じようなコードを書き続けていました。皆様はこのような場合にスニペットを用意したいと思います。そして、IntelliJ IDEAにはLive Templatesという機能があります。
Live Templatesの設定
Templateグループの作成
IntelliJ IDEAには多くのプログラミング言語・ツールに対応したTemplateグループが存在していますが、Terraform用のTemplateグループは存在しませんでした。 そのために、まずは以下の画面キャプチャのように[preference] > [Editor] > [Live Templates]に移動して、Terraform用のTemplateグループの作成を実施します。


Templateの登録
Terraform用Templateグループが作成できたら、早速Templateを登録していきます。 Templateグループの新規作成と同様の画面から、以下の画面を参考に今度はLive Templateを選択します。

Live Templateの設定について、入力しなければならないのはAbbreviation、Template text、Defineです。なお、Descriptionという該当Live Templateの説明文を記載する項目がありますが、こちらはOptionalですので特に設定しなくても問題ありません。

まずはAbbreviationですが、これは呼び出すときの名前になります。例えば今回の例では、Lambda関数用のIAM Roleを作成するためのLive Templatesを想定しているため、IAM_Role_Lambdaという値にしています。 次に、Template textですが、これがLive Templatesを利用した際に記述されるコードとなります。僕の場合には以下の内容を記載しています。
resource "aws_iam_role" "" { name = "" assume_role_policy = jsonencode({ Version = "2012-10-17" Statement = [ { Effect = "Allow" Action = ["sts:AssumeRole"] Principal = { Service = "lambda.amazonaws.com" } } ] }) managed_policy_arns = ["arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole"] }
最後に、Defineですが、これは本Live Templatesを呼び出すことのできる言語などを設定することになります。今回の対象はTerraformとなるため、Otherを選択しますが、言語ごとに設定できるので皆さまの用途に応じて選択してください。
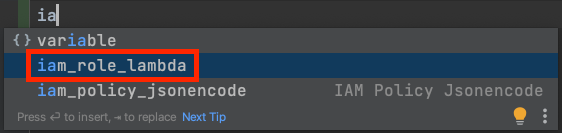
すべての設定を完了
前述の設定を完了すると以下のようにsuggestionされます。選択いただくことで、Template textで設定した内容が記述されます。
さいごに
いかがでしたでしょうか。今回は少し開発環境におけるTipsを記載させていただきました。 皆さまのお役に少しでも立てれば幸いです。
GitHub Actionsで利用するAWS IAM RoleをTerraformで作成する
はじめに
以前投稿したGitHub Actionsの実行に向けたTerraformによるAWS IAM Roleの作成について - 深夜の怠惰な技術ブログにて、GitHub Actionsで利用するAWS IAM ProviderとIAM Roleの作成を記述しましたが、その時はthumbprint_listの部分をハードコーディングしていました。 今回のブログでは、このthumbprintの取得についてもTerraformで記述して、改めて記載していきたいと思います。
TerraformにおけるThumbPrintの取得
data resourceによるGitHubのOIDC Configurationへのリクエストと証明書の取得
該当のTerraformコードは以下のようになります。
data "http" "github_openid_configuration" { url = "https://token.actions.githubusercontent.com/.well-known/openid-configuration" } data "tls_certificate" "github" { url = jsondecode(data.http.github_openid_configuration.body).jwks_uri }
ここについてはOIDCの規格に準拠している処理となりまります。参考までに、https://token.actions.githubusercontent.com/.well-known/openid-configurationに対してcurlでリクエストを実施してみると以下のレスポンスを取得できることがわかります。
curl https://token.actions.githubusercontent.com/.well-known/openid-configuration | jq { "issuer": "https://token.actions.githubusercontent.com", "jwks_uri": "https://token.actions.githubusercontent.com/.well-known/jwks", "subject_types_supported": [ "public", "pairwise" ], "response_types_supported": [ "id_token" ], "claims_supported": [ "sub", "aud", "exp", "iat", "iss", "jti", "nbf", "ref", "repository", "repository_id", "repository_owner", "repository_owner_id", "run_id", "run_number", "run_attempt", "actor", "actor_id", "workflow", "head_ref", "base_ref", "event_name", "ref_type", "environment", "job_workflow_ref", "repository_visibility" ], "id_token_signing_alg_values_supported": [ "RS256" ], "scopes_supported": [ "openid" ] }
IAM ProviderとIAM Roleの作成
前節で記載したdata resourceを参照して、IAM Providerを作成します。該当のTerraformコードは以下のようになります。
resource "aws_iam_openid_connect_provider" "github" { client_id_list = ["sts.amazonaws.com"] thumbprint_list = [data.tls_certificate.github.certificates[0].sha1_fingerprint] url = "https://token.actions.githubusercontent.com" }
あとは、このIAM Providerを参照して、IAM Roleを作成するだけとなります。IAM Roleを作成するためのTerraformコードについては冒頭に貼付したリンクのブログにて記載済みとなりますので、ここでは割愛させていただきます。
さいごに
いかがだったでしょうか。みなさまには釈迦に説法かもしれませんが、僕自身の備忘のために記載致しました。
AWS CodeBuildにおけるGitHub Repositoryをソースプロバイダとしてアクセスする方法
はじめに
必要に迫られてAWS CodeBuildのソースプロバイダをGitHub Repositoryにしました。 その際に実施した内容を備忘のために記載したいと思います。なお、AWS CodeBuildの構築とアクセストークンの設定についてはTerraformを使用しました。
実施内容
GitHubにおけるPersonal Access Tokenの作成
まずは、AWS CodeBuildがソースプロバイダとしてGitHubへ接続するためのアクセストークンとしてPersonal Access Tokenの作成が必要になります。
以下の参考ドキュメントをもとに、Personal Access Tokenを作成しましたが、Scopeとしては以下の添付画像となります。これだけとなります。

参考ドキュメント
TerraformによるAWS CodeBuildの作成
次にAWS CodeBuild Projectを作成します。Terraformコードは以下の通りです。 ここでソースプロバイダとしてGitHubのRepositoryを指定している部分はsource内のtypeとlocationになります。
resource "aws_codebuild_project" "this" { name = "github-integration-project" service_role = "<role_arn>" artifacts { type = "NO_ARTIFACTS" } environment { compute_type = "BUILD_GENERAL1_SMALL" image = "<ecr_uri>" type = "LINUX_CONTAINER" image_pull_credentials_type = "SERVICE_ROLE" } source { type = "GITHUB" location = "https://github.com/<organization_name>/<repository_name>.git" buildspec = jsonencode({ phases = { build = { commands = [ "ls -al" ] } } version = "0.2" }) } }
TerraformによるAWS CodeBuildへのアクセストークンの設定
最後にAWS CodeBuild Projectが先に作成したPersonal Access Tokenを使用して指定したGitHun Repositoryへアクセスするための設定です。 ここで注目するべきは、特にAWS CodeBuild Project自体を識別するための情報が存在しない点です。 理解してしまうとなんてことはないのですが、本設定はリージョンに対してサーバタイプ(GitHub)ごとに1種類しか登録できないのです。
resource "aws_codebuild_source_credential" "this" { auth_type = "PERSONAL_ACCESS_TOKEN" server_type = "GITHUB" token = "<personal_access_token_value>" }
さいごに
いかがでしたでしょうか。これによりAWS CodeBuildはソースプロバイダをGitHub Repositoryとすることができます。 どこかの誰かの参考になれば幸いです。
GitLab CI/CDにおけるJobの手動実行について
はじめに
今回はGitLab CI/CDにおけるJobの手動実行について投稿したいと思います。 この手動実行の用途としては様々あると思います。例えば、Terraformを実行するCI/CDだとして、StageがTerraform PlanとTerraform Applyを実行するJobにそれぞれ分割されていた際に、Terraform Planの結果を確認した後、Terraform Applyを実行するなどではないでしょうか。このように、人手を介してJobの状況を確認して後続のJobを実行するか否か判断する場合に効果を発揮します。しかしながら、注意しなければならないのは、今回お伝えするのは手動実行であり、手動承認ではありません。そのため、Jobを許可や拒否するものでないということです。
Jobの手動実行
対象のJobに対して手動実行する適用するにはwhenにおいてmanualを指定するだけとなります。 manual以外にも指定可能な値は種々ありますが、そのご紹介は以下のリンクをご覧いただければと思います。 以下のコードはサンプルコードになります。
manual_approval:
script:
- echo 'Manual Execution'
when: manual
only:
- main
さいごに
いかがでしたでしょうか。今回はピンポイントの技術検証をお伝えいたしました。 どこかの誰かのお役に立てれば幸いです。